



![]()
1、源代码
合同和财务系统的源码,中文网站和英文网站分别放了一份,大家按需下载即可👇
| 序号 | 项目介绍 | 国内代码(中文版) | 国外代码(英文版) |
|---|---|---|---|
| 1 | 合同和财务系统 | 国内的朋友,点我 | 国外的朋友,点我 |
2、读者群 & 福利
欢迎大家加入读者群




卡塔尔世界杯今晚0点就要开幕了,为了防止大家沉迷工作,忘记看球,小编用50行Python代码写了一个定时提醒你看球的小程序,还有小姐姐语音提醒哟~🎇
👇代码运行效果如视频所示👇
赶紧去领取源代码吧,关注下面的公众号:程序员晚枫,在后台发生关键词:世界杯,就可以24小时自动获取全部代码啦~
获取上面的源代码,在PyCharm里打开,其中重点逻辑介绍如下。👇
1 | toaster.show_toast( |
1 | webbrowser.open_new_tab(url) # 打开浏览器 |
1 | office.video.video2mp3(path='./video.mp4', mp3_name='song.mp3') |
1 | def play_song(song): |
![]()

这个双11花了不到1个w,购买了服务器、域名、DNS、CDN、COS等一堆云服务以后,python-office的官网正式上线了。网站传送门👉https://www.python-office.com
关于这个项目的介绍,大家可以去看一下之前的文章:开源中国推荐:python-office自动化办公,每个功能只需一行代码,做到了真正的开箱即用。这里就不再重复了。
本文主要介绍一下这个网站的源码获取方式和搭建过程,大家也可以轻松上线一个自己的自动化办公网站~
网站源码全部免费开放在了GitHub,国内的gitee也放了一份,大家可以免费下载,记得点个star哟:
https://github.com/CoderWanFeng/python-office.comhttps://gitee.com/CoderWanFeng/python-office.com不会下载的同学,可以看一下下面这个网站,傻瓜式操作即可下载。👇
按顺序,运行以下命令即可。
1 | git clone https://github.com/CoderWanFeng/python-office.com.git |
运行后,可以在http://localhost:18001进行查看。
因为没有逻辑操作,所以该网站目前使用了纯静态页面的形式,技术框架是:vuepress,文章内容编写只需要md和html即可。
目录结构如下图所示,你需要重点关注的是:
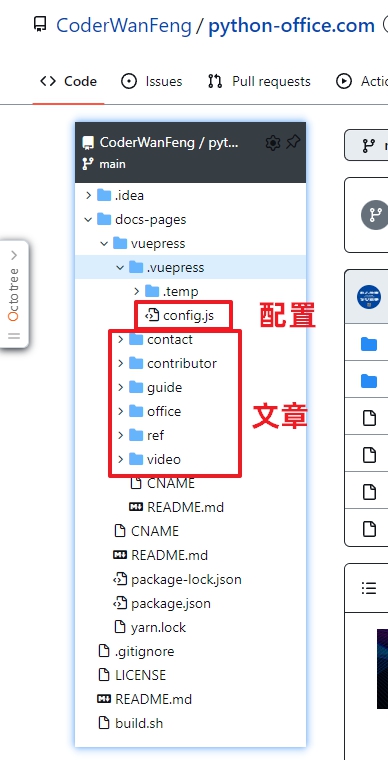
我这里是部署在腾讯的云服务器上,微信里就可以进行各种操作。正好这个双十一在搞活动,新用户50元就能买1年的服务器,非常划算。
大家可以长按下图,直接扫码购买。👇使用过程中遇到问题,也可以加入读者群进行沟通交流:交流群。

很多朋友好奇,做开源项目、个人网站图啥呢?不可能光投入不收益吧?
互联网里有一句话,叫做羊毛出在猪身上。除了游戏和直播,互联网行业里很多产品赚钱的方式,都是对用户免费、对商家收费。之前我以公众号和小红书为例,讲过一些互联网副业的逻辑,有兴趣大家可以看看。
另外,这只是一个副业,而且和本职工作有关,即使最后赚不到钱,也没什么坏处。你说是嘛?


![]()
云盘下载(永久有效)
Python自动化办公 视频 教程:https://www.bilibili.com/video/BV1pT4y1k7FH
🚸 免费Python学习交流群👉 进群 👈
maven仓库:https://mvnrepository.com/
代码规范:https://developer.aliyun.com/live/1201
类加载顺序:https://blog.csdn.net/weixin_44843569/article/details/121616483
Java程序员如何写简历? - 敖丙的回答 - 知乎
https://www.zhihu.com/question/23527137/answer/1008285022
mysql优化:https://www.bilibili.com/video/BV1iq4y1u7vj/?p=159
redis:雪崩、击穿
mybatis中#和$的区别
联合索引和多个索引的区别
多线程和锁:乐观锁(redis锁)
jvm:堆栈的区别
微服务:
服务熔断、降级
组件和服务调用
红黑树为什么用
垃圾回收的区别
mr中矩阵计算的逻辑
ioc、aop
设计模式:观察者模式、适配器模式
mysql有哪些事务?
boot的常用注解
boot的加载顺序
gc:CMS和G1
深拷贝怎么实现?
数据库优化
get和post的区别
1、java基础:https://www.bilibili.com/video/BV1fh411y7R8/?p=633
2、mybatis boot mysql:
mysql:https://www.bilibili.com/video/BV13p4y1Q74y/
mybatis:https://www.bilibili.com/video/BV1mW411M737/?p=6
boot:https://www.bilibili.com/video/BV19K4y1L7MT/?p=34
3、docker & k8s & nginx
docker
4、redis:https://www.bilibili.com/video/BV1Rv41177Af/
5、设计模式:https://www.bilibili.com/video/BV1G4411c7N4/
6、数据结构和算法:https://www.bilibili.com/video/BV1E4411H73v/?p=2
7、cloud:https://www.bilibili.com/video/BV18E411x7eT/?p=95
操作系统:https://www.bilibili.com/video/BV1uW411f72n/?p=28
计算机网络:https://www.bilibili.com/video/BV1c4411d7jb/?p=28
netty:https://www.bilibili.com/video/BV1DJ411m7NR/?p=4
dubbo:https://www.bilibili.com/video/BV1ns411c7jV/?p=25
java版本:https://www.oracle.com/java/technologies/java-se-support-roadmap.html
java11的新特性:https://mp.weixin.qq.com/s/meI2E2UBoflzXi1Ow4Fr1Q
jdk、jre、jvm的关系:https://blog.csdn.net/qq_47183158/article/details/123485244






![]()


大家好,这里是程序员晚枫,今天给大家分享一个爬取微博的项目。
只用了一个框架:Scrapy
教程:https://www.bilibili.com/video/BV1LV411m7Ym
用户信息采集
1 | cd weibospider |
用户粉丝列表采集
1 | python run_spider.py fan |
用户关注列表采集
1 | python run_spider.py follow |
用户的微博采集
1 | python run_spider.py tweet |
微博评论采集
1 | python run_spider.py comment |
微博转发采集
1 | python run_spider.py repost |
基于关键词的微博检索
1 | python run_spider.py search |
运行之前,改一下自己的cookie。

重复性任务总是耗时且无聊,想一想你想要一张一张地裁剪 100 张照片或 核对、纠正拼写和语法等工作,所有这些任务都很耗时,为什么不自动化它们呢?在今天的文章中,我将与你分享 5 个 Python 自动化办公的快捷功能。
所以,请你把这篇文章放在你的收藏清单上,以备不时之需,现在,让我们开始吧。
网友:早知道就好了
有时候我们想编辑PDF,但是很多编辑软件需要收费,这时候我们可以先把PDF转换成Word文档。
1 | pip install popdf |
代码
1 | import popdf |
辛苦设计的100张图片,传到网上容易被盗版怎么办?用Python批量添加浅浅的水印。
安装第三方库
1 | pip install poimage |
代码
1 | import poimage |
这个功能是防疫期间开发的:根据身份证号码,从100个Excel文件里面,找到这个人的所有信息。
安装第三方库
1 | pip install poexcel |
代码
1 | import poexcel |
一行代码,实现网上图片的下载
安装第三方库
1 | pip install poimage |
代码
1 | import poimage |
安装第三方库
1 | pip install wftools |
代码
1 | # 导入这个库 |
以上功能,都来自python-office这个自动化办公的专用库,更多功能和视频教程,可以访问官网:www.python-office.com
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true
